![]()
![]()
摘要:本文综合评介了国外八大双语平行语料库的构建和应用,说明了各个语料库的优势与不足。作者认为,国外双语语料库研究起步较早,在语料库技术和研究方法上有相当积累,但也显示出一些局限性:1)语料库规模较小,语料代表性有限;2)研究的切入点不够,基于双语库的语言类历时研究阙如;3)专门语料库的研制与应用滞后;4)双语库基础上的应用研究和相关技术开发不足。文章指出,上述问题正是今后研究之课题,为超大型、多用途的双语平行语料库的构建与应用提供了思路。
关键词:双语平行语料库;研制与应用
Construction and Application of Parallel Corpora: Issues and comments
Abstract: The paper makes a comprehensive review on the construction and application of 8 major bilingual parallel corpora in the world. Some pitfalls in the corpus-based researches are revealed despite their rich experiences in technology and research method. The issues are manifested as follow: 1) the size of the corpora is not big enough to be representative; 2) research topics are not as varied, especially in respects of language and translation research from a historical perspective; 3) corpora for special purposes are less developed; 4) researches in application and technology based on a parallel corpus still wait to be done. The questions above turned to be the topics to discuss, the authors think, and are conducive to researches on the construction of a large-scale and multipurpose corpus.
Keywords: parallel corpus, construction and application
1 引言
20世纪90年代初,世界上第一个双语库在加拿大建成。1998 年,哈尔滨工业大学建成容量3万句对的英汉双语语料库。可见国内外双语库构建时间相差不远。但双语库应用于语言和翻译研究在国外起步较早,建库的同时许多相关的研究已经展开。经过20年左右的发展,国外双语库在技术和研究方法有了相当多的积累,建立了一批有代表性的双语平行语料库,产生了一大批基于语料库的研究成果,形成了多个研究团队,相互间对相同课题展开了深入的讨论,推动了语料库翻译学作为一个新型研究的发生和发展。同时,我们也发现国外在双语语料库研制与应用方面还存在诸多不足之处。本文在概述国外八大双语库的构建和应用的基础上,点评国外这方面研究的得与失。所概述的问题既可能是将来研究的课题,也可为我们构建超大型、多用途的双语平行语料库提供一些思路。
2 国外八大双语语料库概况
2.1 加拿大议会会议录英-法平行语料库
加拿大议会会议录英-法平行语料库(the Canadian Hansard Corpus)被认为是世界上第一个双语平行语料库,建成于上世纪90年代初,语料主要为加拿大议会的辩论记录,是一个英-法平行语料库。此语料库也是世界上第一个非限制性(unconstrained)语料库,语料规模不断增加,建成初期规模约为1百万词,内容为70年代中期的加拿大议会会议日程的官方记录。之后很快扩展到2千6百万词,时间跨度从70年代中期至1987 年,语料内容主要限于立法方面的话语,但议题涉及较广,除立法建议和事先有准备的演讲外,还包括即席讨论、书面函电、听证会等(参见Roukos et al. 1995;McEnery & Wilson 2001:168)。该语料库的语料来源主要为两个途径的二手文本,一个是IBM的托马斯•J•沃森研究中心(IBM T. J. Watson Research Center),另一个则是Bell通讯研究有限公司(Bell Communications Research Inc./Bellcore)。到90年代初,该语料库库容进一步扩大到法英双语共9千万词(Kenny 2001:114)。
加拿大议会会议录英法平行语料库已被应用于对齐算法(alignment algorithm)(如Church et.al. 1993)、“假朋友”(faux amis)考察,以及机读双语词典词汇信息研究(如Klavans & Tzoukermann 1995)等方面。
此双语库主要是以会议录音转写的书面文本,这样的文本已经大为范化(normalised),一些口语语料库中较为常见的停顿、中断和张口出错(false starts)等现象在此语料库中被去掉了,因此更像是一个笔译语料库(McEnery & Wilson 2001:168)。也就是说,此语料库是一个口、笔语混杂的语料库,就语料而言,无论作为口译还是笔译语料库都缺乏一定的代表性。此语料库主要被应用于计算机语言处理方面,在语言对比和翻译研究方面的应用较少。
2.2 克姆尼茨英-德翻译语料库
克姆尼茨英-德翻译语料库(Chemnitz E-G Translation Corpus)项目开始于1993年,是一个分别以英语和德语为源文本及对应目标文本的双语双向平行语料库,也就是说包括英语原文与对应的德语译文、德语原文与对应的英语译文四类语料。目标库容150万词,但到2001年为止仅达到50万(Kenny 2001:114)。语料包括从当代英美文学到科学教科书,类型多样。此项目旨在创建一个机读并经过对齐的语料库,来发现介词、功能动词、指示成分、隐喻或文化局限结构等一系列语言项的翻译对应项,并做出归类。在此基础上探究影响每一类语言现象各类因素配置的规律性。除了语言结构对比和翻译过程认知方面的理论探讨外,研究结果还应用于双语词典编纂、语言教学和翻译辅助工具研发。现有源于此项目的一个教学工具就是一套基于语料库的克姆尼茨因特网对比语法(Chemnitz Internet Grammar)。此项目是在与其它几个类似的翻译语料库项目合作基础上进行的,有利于促进相近语言之间在翻译研究、语料库语言学和对比分析方面的进展。合作项目包括伦敦-隆德语料库(the London-Lund corpus)中的英语-瑞典语和兰卡斯特-奥斯陆-卑尔根语料库(The Lancaster-Oslo-Bergen Corpus )中的英语-挪威语语言结构分析,于是英语与德语、瑞典语和挪威语这三种日尔曼语之间的对比研究就可以在同一模式下进行。
以此语料库为基础的研究主要涉及翻译与认知结构、翻译共性、文化局限语项、搭配词、对比语法等方面(详见Schmied 1994,1998,1999;Schmied & Schaffler 1996;Schaffler 1997;Smitterberg et al. 2000等;The English/German Translation Corpus: The project http://www.tu-chemnitz.de/phil/english/chairs/linguist/real/independent/transcorpus/index.htm)。
此平行语料库研制初期的主要目的是用于语言对比研究和应用研究,主要是从词汇对比入手,进而关注修辞和搭配。基于此语料库的研究成果表明,他们对翻译的关注只是作为一种研究手段,最终目的是语言研究,研究结果也主要应用于双语词典编纂、语言教学和翻译辅助工具的研制与开发。
2.3 德英文学文本平行语料库
德语-英语文学文本平行语料库(German-English Parallel Corpus of Literary Translation,GEPCOLT)是一个德译英单向双语平行的文学文本语料库。建库的初衷是为了进行翻译文本中词汇范化(lexical normalisation)和词汇创造性(lexical creativity)的考察。语料限制在叙事小说文本方面,主要出于两个方面的考虑:第一,有现成的德英小说翻译的抽样模式;第二,前人对于翻译小说文本的研究已经关注到对范化问题,说明翻译小说文本是这类研究的一个理想文类。语料主要是20世纪80至90年代出版的当代德国文学作品的英译,当时(到2001年)的库容为,源文本与译文本共约2百万词(其中德语文本970,270形符,英语译文1,055,021形符)(Kenny 2001:114)。
该语料库借鉴翻译英语语料库(TEC)中篇头文件(header files)的做法,标注了有关文本出版和翻译过程等文本外信息(参见Olohan,2004:58-59)。
此语料库主要应用于翻译共性问题的考察。例如,Kenny(2000)以GEPCOLT为基础对德文原语文本中特定创造性复合词及搭配(creative compounds and collocations)在德英翻译中范化情况进行探讨,结果表明在七个个案中有两个的确发生了范化,只是尚不能根据有限的个案做出笼统的归纳。
Kenny(2001)以GEPCOLT为基础对翻译中的范化和译者创造性进行考察,她发现翻译中的确存在词汇范化现象,而原语文本中的创造性词汇在大多数情况下却没有发生范化(2001:187、210)。这说明对范化现象的研究还是不能完全脱离源语语篇的因素。针对Olohan & Baker(2000)采用的类比语料库方法,Kenny(2005)以德英文学文本平行语料库对其非强制性that研究结果进行重新验证后指出:英语译者在say之后使用非强制性that的大多数情况并非为了去对应德语中的daβ,乍看起来属于语法上的显化,但还需要确认原语文本中是否使用了除daβ以外的其它连接词形式来明示从句的叙述性质,如果有的话,就很难断定英语译文中包含that的做法全都属于显化的现象 (Kenny 2005:161)。
GEPCOLT的语料仅限于小说文本,从内容上既属于一般语言语料库,也属于专门文体语料库。此语料库最大的特点是:研究目标决定建库类型。在此语料库基础上的研究主要限于翻译共性,尤其是范化方面的研究。GEPCOLT语料单一,而且为单向平行,语料规模较小,仅约2百万词。目前的研究还仅限于词汇方面,对搭配、句法等问题的研究尚未开展。
2.4 英语-挪威语平行语料库
英语-挪威语平行语料库(English-Norweigian Parallel Corpus,ENPC))是一个双向平行语料库,由挪威奥斯陆大学(University of Oslo)文学院和英美研究系研制,研究团队的主要成员包括:奥斯陆大学的Stig Johansson,卑尔根(Bergen)挪威人文学科计算中心(Norwegian Computing Centre for the Humanities)的Knut Hofland,以及奥斯陆大学的研究助理 Jarle Ebeling和Signe Oksefjell。语料包括英语原文及其对应挪威语译文,和挪威语原文及其对应英语译文四类文本,这一点与克姆尼茨英-德翻译语料库相似。研制的目标是以对应语料库为核心,结合类比的非翻译语料库进行语言对比研究和翻译研究。文本采用抽样的方式,每一个完整文本节选1-1.5万词的篇幅,包括文学和非文学文本两大类,文学文本以小说文本为主,全库共100个源文本和100个对应的译文本,总库容为260万词(见表-1)。源文本与对应译文本实现句子层级对齐,由Knut Hofland 所开发的程序自动对齐,之后经过人工校对,贮存在数据库中,使用Jarle Ebeling 开发的翻译语料库浏览器(Translation Corpus Explorer)进行检索。
该语料库为开放语料库,在资源允许的条件下库容会继续扩大。研究者对源文本和译文本都做了词汇标注。
表-1 ENPC的语料构成(参见Johansson 1999/2002: 3)

ENPC项目开始于1994年,完成于1997年。1997-2001年期间,该语料库的语料收集扩展到德语、荷兰语和葡萄牙语。ENPC的标注系统采用《电子文本编码语转换指南》(Guidelines for Electronic Text Encoding and Interchange)所提出的TEI(Text Encoding Initiative)格式,即XML格式(Sperberg-McQueen & Burnard, 1994)。各层次文本开始与结束分别用<..>和</..>标出,最常用的就是段落标记(<p>...</p>)和句子标记(<s>...</s>)。
该语料库基础上的研究内容包括:英语与挪威语中的显现结构(presentative constructions)对比、英语与挪威语中的语序和信息结构、英语与挪威语词汇对比、同文类文本跨语言对比、翻译文本与目标语中非翻译文本的对比、翻译语言共性等方面。以翻译文本作为研究对象,目的不在于揭示翻译错误,而是将翻译产品作为语言对比研究和翻译研究的资源。Ǿveras(1998)以英语-挪威语平行语料库为基础,以Blum-Kulka(1986)的显化假设为出发点,对词汇和语法两方面的显化进行了考察,重点放在词汇衔接上,以揭示抛开语言差异的翻译语言的具体特征,最终目标是试图得出关于目标语语言社团中所盛行的文学翻译规范。
ENPC的建库理念比较成熟,英语、挪威语文本实现双向对应,英语原文与对应挪威语译文、挪威语原文与对应英语译文这四类文本可以提供语言对比研究和翻译研究所需要的语料。文本实现了句对齐,所采用的XML标注适用于多类检索。其局限性在于语料收集采用抽样的方法,对语言的衔接性有一定的影响,语料范围也不够广泛。此外,其研究目标较多而语料库相对较小,有力不从心之感。
2.5 英语-瑞典语双向平行语料库
英语-瑞典语双向平行语料库(The English-Swedish Parallel Corpus,ESPC)的构建开始于1993年,在隆德大学(Lund University)展开,得到瑞典人文与社会科学研究委员会(Swedish Council for Research in Humanities and Social Sciences)的资助。自1997年起,哥德堡大学(Göteborg University)加入该项目。主要成员有和隆德大学的Bengt Altenberg、Mats Johansson、Mikael Svensson教授和哥德堡大学的Karin Aijmer教授。该项目与英语-挪威语平行语料库(ENPC)和翻译芬兰语语料库(Corpus of Translated Finnish)项目都有沟通与合作。该语料库同ENPC一样包括英语原文及其对应瑞典语译文,和瑞典语原文及其对应英语译文四类文本语料,可以开展多类型语言对比与翻译研究。该语料库2001年的规模为2千8百万词,包括64个英文文本抽样及其对应瑞典语译文和72个瑞典语文本抽样及对应英语翻译文本。每个文本抽样通常为10,000-15,000 词,部分篇幅较短的非小说文本采取全文收录。
该语料库文本选择遵循如下原则:1)以当代语言为主,不局限于特定地区语言变体;2)包含多种文本类型、多位作家和译者;3)双语文本在文类、主题、读者对象、语域等方面具备类比关系;4)节选文本选择作品开头或结尾部分的连贯章节;5)尽可能保证所选英语文本除有对应瑞典语翻译文本外,还有挪威语和芬兰语译本。最后一点主要考虑将来与ENPC之间开展两种关系密切的语言在语言类型学上的对比研究,以及与不同族的芬兰语的对比研究。ESPC包含的文本类型比较丰富(如表-2所示),分为小说和非小说两大类,
表-2 ESPC语料的文本类型构成(参见Altenberg et al. 2001)
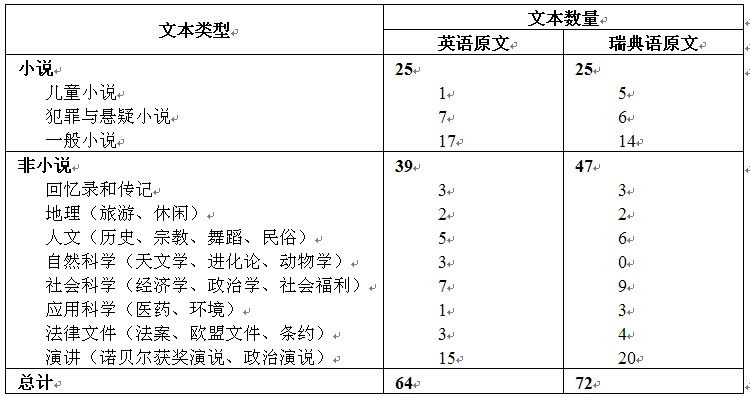
小说文本又分为儿童小说、犯罪与悬疑小说和一般小说三类,非小说类又包括回忆录与传记等8类,若干子类,几乎涵盖了各个领域的文本,有利于开展特定文本或专门用途文本的语言与翻译研究。ESPC基础上的研究,除大量的语言对比分析外,与翻译相关的研究涉及翻译体、附加疑问句、被动语态、动词熟语、分裂句、定式与非定式结构等的语际转换考察(如Aijmer 2001;Axelsson 2006;Fredriksson 2006;Gustawsson 2006;Johansson 2001,2002;Ruin 2001等)。
ESPC语料规模较大,文本类型比较丰富,有利于开展多文类的语言对比与翻译研究。其最突出的一点,就是在建库时就已经考虑到与其它语对语料库之间的交叉研究,更大地发挥了语料库的作用。其局限性表现在,尽管文类比较丰富,但语料以抽样为主,而且从表-2可以看出,具体的子文类文本数量较小,缺乏一定的代表性。
2.6 英语-意大利语双向平行语料库
英语-意大利语双向平行语料库(Corpus of English-Italian translation,CEXI)1990年代后期由意大利博洛尼亚大学弗利校区(University of Bologna(Forlì))负责研制,是一个双向对应的平行语料库,语料中一半为英语源文本及其对应的意大利语译文本,另一半为意大利语源文本及其对应的英语译文本。该语料库为翻译驱动的语料库,即语料选取以目标文本为导向。此语料库作为一个学习语言、文化和翻译的资源,其建库目的主要是从描写和应用视角出发的语言学习和译员培训,使学生和研究者能更多地了解翻译过程和翻译产品。
CEXI的设计以英语-挪威语平行语料库(ENPC)为基础模式,实现句子层面的对齐,不仅用于平行检索,还应用于同一语言内翻译文本与非翻译文本的对比、跨语言对比、跨语言翻译研究。语料包括文学(或虚构文本)与非文学(信息性文本)两大类,主要为散文(prose),不包括诗歌、戏剧等,也不包括自译文本、儿童文学文本、教科书和简写本,时间跨度主要集中在1976-2000年间。语料采用抽样的方法,上述四类文本每个部分80个文本抽样。原计划库容为4百万词。实际收录92个文本(其中文学文本40个,非文学文本52个)的368个抽样(每个文本1-1.5万词),共计460万词,研制者计划从文本范围、数量和类型等几方面继续扩大语料库的容量(参见Zanettin 2002)。
Bernardini & Zanettin(2004)以英语-意大利语双向平行语料库(CEXI)为例指出,目前大多数基于语料库的描写翻译研究主要是在单语类比语料库的模式下进行,由于社会文化等因素的制约,保证语料的类比性是一个很棘手的问题,比如两种语言在对方文化中的社会地位不尽平等、原文与译文的年代相差过于久远等,在此类语料基础上的研究结果必然会受到一定影响。
CEXI的设计以英语-挪威语平行语料库(ENPC)为基础模式,双语双向平行,句级对应。语料同样采用抽样,规模较小。其中最突出的一个问题就语料的不平衡。如Zanettin(2000)的研究表明,以意大利语出版的图书中,翻译作品的数量远远大于原创作品,其中一半是译自英语,而以英语出版的图书中翻译作品所占的比例却要小得多,其中译自意大利语的作品还不足5%。而且两种翻译作品在各自的目标语文学系统中所享有的地位也不相同,译自英语的意大利语作品是意大利流行小说的主宰形式,而译自意大利语的英语作品在英语世界并没有同样的地位。因此,倘若从翻译作品中选择意-英双向平行语料库的语料,它们就缺乏一定的可比性。
2.7 葡萄牙语-英语双向平行语料库(English-Portugese Parallel Corpus(Compara))
葡萄牙语-英语双向平行语料库也是以英语-挪威语平行语料库(ENPC)为蓝本设计的一个双向对应的平行语料库。包括英语源文本及其对应葡萄牙语译文本,以及葡萄牙语源文本及其对应英语译文本四类语料,对应文本实现句子层面对齐。建成初期仅包括文学文本,但其它文类陆续收录。文本按照德国斯图加特大学(University of Stuttgart)研发的IMS语料库工作平台系统(IMS Corpus Workbench system)进行编码,并且可以通过“葡萄牙语语言计算处理”项目所设计的“葡萄牙语计算机处理工程”(Computational processing of Portugese project)的DISPARA界面进行在线检索。
Frankenberg-Gacia(2004)以葡-英双向平行语料库(Compara)为基础,从译文与原文文本长度角度探讨了非强制显化问题。通常认为非强制性显化往往表现为添加额外词汇,Frankenberg-Gacia的研究以定量分析的方法证明了翻译文本中词汇数量的整体增加表明译文往往比原文更为明晰,而且这并不受制于两种语言之间的差异。此语料库规模也不太大,目前开展的相关研究不多。
2.8 欧洲议会口译语料库
欧洲议会口译语料库(The European Parliament Interpreting Corpus,EPIC)是由意大利博洛尼亚大学翻译语言和文化研究小组负责研制的一个开放的包括英语、意大利语和西班牙语的三语平行语料库。语料库建成于2004年,包含英语、意大利语和西班牙语以及每种语言同声传译的其它两种翻译语言,这样就构成了一个复合的平行或类比对应关系,研究者可以根据需要任意选取组合,对翻译现象进行三角考察。语料内容主要为一种语言的议会发言及其对应的另一种语言的翻译文本,所有语料都经过POS 词类标注处理。
语料内容来自欧盟议会全体会议的口译录音,共有140个4小时的录影带,这些音像资料包括全体会议中的源语演讲(标识为“Org”)以及英语,意大利语和西班牙语声道的同声传译(标识为“Int”),亦有欧洲议会的新闻发布会的传译内容。语料文本主要参考欧盟在会议后发布的详尽的官方稿件,完成文字初稿,再经审阅而得。口译录音的转写采用同传培训中经常使用的影子跟读方法,一边听口译员的录音,一边大声重复他们的译文,同时利用语言识别软件将复述的言语自动输出文字稿。译文中的副语言特征(paralinguistic features)则由研究者补充完成。语料均带有篇头(header)标注,包含与口译输出相关的信息,如言语的长度(长、短或中等)、发言模式(即兴、带稿或两者兼有)和平均速度(快、中等、慢)以及有关讲者的名字、国籍、性别和政治背景等,用作检索的参数之一。EPIC语料库采用POS标注,意大利语和英语的文本用的是Treetagger软件,西班牙语文本采用Freeling软件。建成之后的语料库共涵盖三个源语文本(分属意大利语、英语和西班牙语)的子语料库和六个译语文本的子语料库(参见李婧、李德超 2010:101-102)。
3 国外双语语料库研制与应用评述
从以上述评可以看出,国外双语语料库在研制与应用方面起步较早,已经在语料库技术和研究方法上有了相当的积累。但国外双语语料库的构建和应用方面也存在诸多问题,主要表现出如下特点:
第一,语料库规模较小,语料代表性有限。
库容方面,一些主要的语料库在建库初期的规模都较小,千万词以上的大库不多。如,克姆尼茨英-德翻译语料库项目开始于1993年,目标库容150万词,但到2001年为止仅达到50万(Kenny 2001:114);德语-英语文学文本平行语料库(GEPCOLT)到2001年)的库容为约2百万词;英语-挪威语平行语料库总库容为260万词;英语-意大利语双向平行语料库到2000年左右库容为约460万词。但许多语料库都定位为开放式语料库,在不断增加文本的收入量。
代表性问题包括模式(mode)、文类(genre)、时间跨度(time span)、语料选材等方面。总体而言,书面语语料库多于口译语料库,主要原因在于口译语料库建库难度相对较大。文类上以文学文本为主的通用型语料库较多,语料时间跨度小。
以口译语料库为例,加拿大议会会议录英法平行语料库的语料主要为根据录音转写的书面文本,口语文本中较为常见的停顿、中断和张口出错(false starts)等现象在转写时被去掉了,文本在很大程度上已经被范化(normalised)(McEnery & Wilson 2001:168)。这样的语料库并非完全真实的语料,用于口译研究,难免会有一些误差。欧洲议会口译语料库(EPIC)语料文本主要参考欧盟在会议后发布的详尽的官方稿件,完成文字初稿,再经审阅而得。但对口译录音的转写采用同传培训中使用的影子跟读方法,一边听口译员的录音,一边大声重复他们的译文,同时利用语言识别软件将复述的言语自动输出文字稿,译文中的副语言特征(paralinguistic features)则由研究者补充完成(参见李婧、李德超 2010:101)。由此看来,这样的口译语料依然是从实验环境下得来,尽管可以在一定程度上描写口译过程,但这与真实情景下的口译过程还存在一定的差异。
文类方面,大多语料库定位为通用语料库,但语料来源较为单一。如克姆尼茨英-德翻译语料库的语料包括从当代英美文学到科学教科书等类型;德语-英语文学文本平行语料库(GEPCOLT)的语料限制在叙事小说文本方面。英语-挪威语平行语料库包括文学和非文学文本两大类,文学文本以小说文本为主;英语-意大利语双向平行语料库的语料包括文学(或虚构文本)与非文学(信息性文本)两大类,主要为散文(prose),不包括诗歌、戏剧等,也不包括自译文本、儿童文学文本、教科书和简写本,时间跨度主要集中在1976-2000年间;葡萄牙语-英语双向平行语料库建成初期仅包括文学文本;英语-意大利语双向平行语料库时间跨度主要集中在1976-2000年间。而且以上所述大多数语料库都采用抽样的方法来采集语料,使语料的代表性收到一定限制。
第二,研究切入点不够,基于双语库的语言类历时研究阙如。
双语平行语料库研制初期,基于双语库的研究主要侧重于语言对比,尽管也涉及到一些翻译研究,但主要是与机器翻译或计算机文字处理的辅助研究。研究的切入点主要在词汇方面,研究成果的应用主要是词典编纂、语法研究等。2000年以后,对翻译语言特征、语言共性等方面的关注越来越多。主要原因在于,为了区别于传统的源文本-目标文本的语际对比模式,语料库翻译学发展初期主要采用目标语中翻译文本与非翻译文本比较的语内类比模式。之后一些学者(如Kenny 2001,2005)建议将平行语料库重新引入语料库翻译研究中,作为对类比模式的补充。目前的研究课题依然主要放在翻译共性和译者风格方面。随着语料库规模的不断扩大,时间跨度可以作为一个参数来考察翻译语言或翻译给原创语言的历时变化。近年来,除了翻译共性和译者风格外,通过语料库方法探索翻译对语言的影响开始成为语料库翻译研究的一个新课题(参见黄立波、王克非 2011:917-918)。
第三,专门语料库的研制与应用滞后。
资金、版权、人力、技术等因素对语料库的规模有一定的限制。各主要双语库对专门类型的文本都有一定程度的收录,但在数量上还远不能满足现阶段各专门用途类翻译理论研究与应用研究的需求,语料的文类对研究结果有一定的影响。目前国际上大多语料库还仅限于文学和非文学两种,较为笼统。文学文本则以小说、散文为主,非文学作品则以新闻、政论、科技等为主。对文学文本之下的戏剧、诗歌等,以及非文学文本中的财经、法律、历史、农林、医药等文类细化不够。近年来,对专门文类语料库的关注开始显现。一些研究中的语料已不仅限于文学与非文学的划分,而是涉及商业、旅游、医学、以及航空等具体文类。
第四,双语库基础上的应用研究和相关技术开发不足。
大型的双语库还很少应用于教学研究和译员培训等方面,尤其表现在:1)这些双语平行语料库大都有在线检索平台,但以这些双语库为基础建立的教学平台则很少。现有的平台仅能提供词语、搭配、句对等简单检索,利用率不高。随着今后语料标注与加工技术的发展,更加完善的检索平台应该能够提供更多类型的多重检索服务;2)口译语料库研究的最终目的,是在对口译现象进行描写和解释的基础上,达到将研究成果应用于翻译教学和译员培训,开发以双语口译语料库为基础的教学或培训平台,目前此类研究在理论上已取得了一定成果,但相关的应用研究尚未大规模展开;3)现有的翻译教学软件大多为翻译记忆软件,适用性和效果还存在不少问题。双语库可以作为翻译教学软件的丰富资源,但目前以双语库为基础的翻译教学软件尚不多见。一个原因是版权的限制,另一个原因则是标注技术的局限,使得有利于课堂教学的翻译现象的计算机提取还不完善。
4 结语
语料库翻译学是语料库语言学与描写翻译研究相结合基础上发展起来的,前者为这一新研究范式提供理念和技术支持,后者则为其提供研究课题。因此,新型语料库的开发与研制是今后语料库翻译学取得新突破的硬件基础,双语库在翻译研究中的潜力还有待于进一步开发。上述对国外双语语料库的述评和讨论,其实也提出了不少今后研究的课题,如何更好的构建超大型、多用途的双语平行语料库,是国内外学界的一项新课题。同时,进一步注重方法论也是语料库翻译学研究的新趋势。
参考文献
Aijmer, K. 2001. Probably in Swedish translations—a case of translationese[A]? In S. Allén, S. Berg, S.-G. Malmgren, K. Norén & B. Ralph (eds.). Gäller stam, suffix och ord[C]. Göteborg: Meijerbergs institut för svensk etymologisk forskning, 1-13.
Altenberg, B., K. Aijmer & M. Svensson. 2001. The English-Swedish Parallel Corpus (ESPC): Manual of enlarged version[OL]. http://www.sol.lu.se/engelska/corpus/corpus/espc.html (acessed on 15/03/2012).
Axelsson, K. 2006. Tag questions in English translations from Swedish and Norwegian—are there differences[A]? In B. Englund-Dimitrova & H. Landqvist (eds.). Svenska som källspråk och målspråk[C]. Göteborg: Översättarutbildningen vid Humanistiska fakulteten, 4–21.
Bernardini, S. & F. Zanettin. 2004. When is a Universal not a Universal? Some limits of current corpus-based methodologies for the investigation of translation universals [A]. In A. Mauranen and P. Kujamäki (eds.). Translation Universals — Do They Exist [C]? Amsterdam: John Benjamins, 51-62.
Blum-Kulka, S. 1986. Shifts of cohesion and coherence in translation[A]. In J. House & S. Blum-Kulka (eds.). Interlingual and Intercultural Communication. Discourse and Cognition in Translation and Second Language Acquisition Studies[C]. Tübingen: Gunter Narr Verlag, 17-35.
Frankenberg-Gacia, A. 2004. Are translations longer than source texts? A corpus-based study of explicitation[A]. Paper presented at the Third International CULT (Corpus Use and Learning to Translate) Conference, Barcelona, 22-24 January 2004[OL]. http://www.linguateca.pt/Repositorio/ Frankenberg-Garcia2004.doc (accessed 04/07/2006).
Fredriksson, A. 2006. On passives and translation strategies in parallel texts[A]. In B. Englund-Dimitrova & H. Landqvist (eds.). Svenska som källspråk och målspråk[C]. Göteborg: Översättarutbildningen vid Humanistiska fakulteten, 75–91.
Gustawsson, E. 2006. Translation of English verbal idioms into Swedish[A]. In B. Englund-Dimitrova & H. Landqvist (eds.). Svenska som källspråk och målspråk[C]. Göteborg: Översättarutbildningen vid Humanistiska fakulteten, 92–108.
Johansson, M. 2001. Clefts in contrast: a contrastive study of it clefts and wh clefts in English and Swedish texts and translations[J]. Linguistics 39: 547-582.
Johansson, M. 2002. Clefts in English and Swedish. A contrastive study of it-clefts and wh-clefts in original texts and translations[M]. unpublished PhD dissertation. Department of English, Lund University.
Johansson, S., J. Ebeling & S. Oksefjell. 1999/2002. English-Norwegian Parallel Corpus: Manual[Z]. Department of British and American Studies, University of Oslo,
Kenny, D. 1999. Translators at play: exploitations of collocational norms in German-English translation[A]. In B. Dodd (ed.). Working with German Corpora[C]. Birmingham: University of Birmingham Press, 143-160.
Kenny, D. 2001. Lexis and Creativity in Translation: A corpus-based study[M]. Manchester: St. Jerome.
Kenny, D. 2005. Parallel corpora and translation studies: old questions, new perspectives? Reporting that in Gepcolt: a case study[A]. In G. Barnbrook, P. Danielsson & M. Mahlberg (eds.). Meaningful Texts: The Extraction of Semantic Information from Monolingual and Multilingual corpora[C]. London: Continuum, 154-165.
Klavans, J. & E. Tzoukermann. 1995. Combining corpus and machine-readable dictionary data for building bilingual lexicons[J]. Machine Translation. 10(3): 185-218.
McEnery, T. & A. Wilson. 2001. Corpus linguistics: An introduction (2nd edition)[M]. Edinburgh: Edinburgh University Press.
Olohan, M. & M. Baker. 2000. Reporting that in Translated English: Evidence for Subconscious Processes of Explicitation[J]. Across Languages and Cultures 1(2): 141-158.
Olohan, M. 2004. Introducing Corpora in Translation Studies[M]. London: Routledge.
Øverås, L. 1998. In search of the third code. An investigation of norms in literary translation[J]. Meta, 43(4): 571-588.
Roukos, S., D. Graff & D. Melamed. 1995. Hansard French/English[Z]. Philadelphia: Linguistic Data Consortium. (http://www.ldc.upenn.edu/Catalog/CatalogEntry. jsp?catalogId=LDC95T20 accessed on 24/03/2012)
Ruin, I. 2001. Nonfinite versus finite constructions—a problem in the translation of Swedish literary texts into English[A]? In W. Vagle & K. Wikberg (eds.). New directions in Nordic text linguistics and discourse analysis: Methodological issues[C]. Oslo: Novus Forlag, 243-253.
Schmied, J. & H. Schaffler. 1996. Explicitness as a universal feature of translation[A]. In M. Ljung (ed.). Corpus-based studies in English: Papers from the seventeenth International Conference on English Language Research on Computerized Corpora (ICAME 17)[C]. Amsterdam: Rodopi, 21-36.
Schmied, J. 1994. Translation and cognitive structures. Hermes[J]. Journal of Linguistics (13): 169-181.
Schmied, J. 1998. Differences and similarities of close cognates: English with and German mit[A]. In S. Johansson & S. Oksefjell (eds.). Corpora and cross-linguistic research: Theory, method and case studies[C]. Amsterdam: Rodopi, 255-176.
Schmied, J. 1999. Applying contrastive corpora in modern contrastive grammars: the Chemnitz Internet Grammar of English[A]. In H. Hasselgard & S. Oksefjell (eds.). Out of corpora. Studies in honour of Stig Johansson[C]. Amsteram: Rodopi, 21-30.
Zanettin, F. 2002. CEXI. Designing and English-Italian Translational Corpus[A]. In B. Ketteman & G. Marko (eds.). Teaching and Learning by Doing Corpus Analysis[C]. Amsterdam: Rodopi, 329-343.
黄立波、王克非,2011,语料库翻译学:课题与进展[J]. 外语教学与研究》43(6):911-923。
李婧、李德超,2010,基于语料库的口译研究:回顾与展望[J],《中国外语》7(5):100-105。
作者:王克非,北京外国语大学中国外语教育研究中心教授、博士,主要研究语言学和翻译学,电邮:kfwang@bfsu.edu.cn;黄立波,西安外国语大学英语学院副教授、博士,主要研究语料库翻译学,电邮:libohuang2003@yahoo.com.cn。
