![]()
![]()
一、研究进展情况
① 研究计划总体执行情况及各子课题进展情况
2014年7月——2016年7月,是本项目推进的关键时期。项目组按照项目的计划顺利推进,开展研究。
在2年的时间里,总体执行情况如下:完善了知识库的构建,真对名词物性角色,填写了部分词汇的知识;在多级语料库的加工与挖掘方面,在完成规范的制定的基础上,开展了规模化的加工工作;进一步设计了和实现了多个数据加工众包平台,包括指代关系标注,句间关系标注和名词物性角色的填写;在多视角语义分析方面也取得了一系列的成果,包括缩略语识别、实体关系分类与实体链接分析、也开展了不规范文本的语义分析和校对研究的工作。
在2年的时间里,我们已经发表学术论文21篇,包括发表于计算语言学领域和人工智能领域的顶级国际会议。此外,还申请专利3项,申请软件著作权3项。圆满完成了相应时期的任务。
下面分别介绍各子课题的进展情况。
子课题1:基于生成词库理论和论元结构理论的语义知识体系研究
子课题针对常用的名词词条,按照设计的知识库结构进行了知识项的填写,共达一百多万字。每个词条的知识分三个部分:第一部分是对词条百科知识的说明,第二部分是基于生成词库理论,对词条物性结构方面的描述,共包括施成、功用、构成、形式、处置、处置和评价等九种角色;第三部分是根据实际语料,对这些名词的实际句法配位做了穷尽性的例句展示。这样的知识库,不仅有利于中文信息处理中的信息抽取和信息检索工作,也可以作为一种语法学习词典,供本族人和外国留学生学习和查阅使用。
子课题有三位研究生分别围绕现代汉语双宾结构、现代汉语旁格宾语结构和现代汉语名词谓语句等具体语法现象,利用生成词库论的物性结构理论完成了自己的硕士学位论文。相关论文也在投稿发表之中。
在这2年时间里,子课题组在核心期刊上发表相关论文4篇。
子课题2:网络文本的多级加工与语言知识挖掘研究
在近两年,子课题主要围绕以下四个方面开展了研究:
1)制定了多视图的汉语树库标注规范,在人民日报、微博语料上标注了较大规模的汉语树库
2)制定汉语句际关系的标注体系,针对汉语特点提出了解决方案,在人民日报3个月语料上标注了所有的句际关系。
3)对网络语言的处理与挖掘。在词语层面,探讨了情感极性词的自动挖掘与判定方法;在句子层面,对于社区问答中的多小句复杂问句的分割与处理进行了研究。
4)其他相关研究。研究了汉语开放领域的信息抽取方法,提出了基于依存的词语embedding计算方法及其在类比计算中的应用。
子课题3:基于群体智慧的知识资源加工技术及众包平台研究
为便于语料和知识加工,子课题组在近两年内进一步完善并扩展了众包平台的功能,主要研究如下:
1)进一步完善了众包平台的一般性框架构建,包括加工结果的展示模块,语料(知识)加工模块,候选答案推荐模块。
2)进一步完善了加工质量控制模块,包括参与者行为跟踪记录模块。通过日志形式,动态记录用户的行为轨迹。
3)在原有指代消解的基础上,进一步实现了句间关系加工众包平台功能,在实际标注过程中发挥了重要的作用。
4)设计实现了名词基本物性角色标注的众包平台,含有自动标注,答案推荐,错误校正等主要功能。
子课题组已针对平台的设计申请并获批了2项软件著作权。
子课题4:知识与统计相结合的多视角文本语义分析技术研究
网络文本的语义分析技术是不规范语言分析的重要内容,在过去的2年里,子课题主要开展了如下研究:
1)进一步研究了汉语缩略语问题。缩略语是一种非规范的语言表示,也是网络语言的主要形式之一。子课题重点研究了缩略语的分析和挖掘方法。
2)研究了实体关系的抽取与分类、实体挖掘与实体链接等问题。实体语义是不同于词义的一种语义,这种语义直接与现实进行对接。在网络语言中,实体的出现十分频繁。为此,子课题重点研究了实体关系发现、实体关系分类、实体挖掘和实体链接等问题。
3)研究并设计了基于网络社区的问答系统。像百度知道之类的社区问答是互联网中的一种典型服务。社区问答中积累了大量的问题-答案对,其中,很多问题-答案对可能会被反复使用。充分利用这类资源为用户提供再次服务或再次类似服务具体有特别重要的意义。子课题对此进行了深入研究。
4)研究了针对文本表达不规范的分析问题。表达的不规范和用语的临时性是网络文本的主要特点,子课题就网络文本中的不规范性,研究了文本校对方法。
子课题组在这2年的时间里,取得了一系列的研究成果,申请专利3项,软件著作权1项,发表论文8篇。
②调查研究及学术交流情况(调研数据整理运用、文献资料收集整理、学术会议、学术交流、国际合作等)
本项目开始于2013年1月,在2014年6月之前主要是项目的调研,2014年6月之后的2年时间里,调研不是本项目的主要任务,但仍然会根据任务需要开展一些必要的调研,包括资料的收集,数据的整理等。这一阶段,以任务的推进为主,包括上述的研究。在这一时期,项目组参加了一系列的学术活动。具体而言,我们开展的调研和学术交流情况如下:
(1)进一步开展了数据收集和分析:主要包括,大规模命名实体数据的采集,为实体的挖掘和实体关系、属性知识的抽取做了准备;借助于搜索引擎,收集了3种类型的社区问答数据,包括天气问答,航空问答,快递问答。这一数据为本项目开展社区问答的研究打下了良好的基础。此外,还就餐饮行业收集了一定规模的会话数据。
(2)进一步查阅大量的文献资料。深度学习和问答会话是当前自然语言处理研究的热点,本项目结合任务要求,查阅了大量相关的文献和资料,包括相关的培训讲义,获得的相关知识在本项目的开展中发挥了重要作用,形成了多个成果。
(3)参加了多个学术会议。除了项目各子课题进行讨论之外,项目组成员参加了一系列的学术会议,包括2014年8月在都爱尔兰柏林举办的自然语言处理高水平学术会议COLING-2014,2014年10月在卡塔尔多哈举办的高水平学术会议EMNLP-2014,2014年11月在武汉举办的全国计算语言学会议CCL-2014,2014年12月在深圳举办的NLPCC-2014中文计算会议。此外,2015年分别参加在延吉举办的少数民族语言处理会议,本项目负责人王厚峰还应邀作特邀报告。2015年还应哈尔滨工业大学(深圳研究生院)邀请参加学术讨论,受邀到广东外语外贸大学讲座等;2015年还参加知识图谱、CCL-2015, NLPCC-2015等多个学术会议。2016年7月,参加在纽约举办的人工智能顶级学术会议IJCAI-2016。其间,我们就目前正在开展的工作分别同与会人员进行了讨论。
③成果宣传推介情况(成果发布会、《工作简报》报送情况、国家社科基金专刊投稿及采用情况等)
本项目的成果推介形式主要是学术报告,此外,还利用特邀报告重点介绍项目的研究成果,如,在少数民族语言信息处理的学术会议和在广东外语外贸大学的邀请报告。
二、研究成果情况
①代表性成果简介
2014年6月以来,我们继续按照项目任务开展研究,取得了一系列的成果,下面仅介绍5项代表性的成果。
1)知识库的构建
语言知识库建设是本项目的基础,也是语义分析的关键。本项目按照任务要求,进一步按照任务书要求工作。进行了知识的分类,完成一百多万字的填写工作。如下是我们填写的一个词条的例子:
白酒 báijiǔ〈名词,中性〉用高粱、玉米、甘薯等粮食或某些果品发酵、蒸馏制成的酒,没有颜色,含酒精量较高,也叫烧酒、白干儿。
〔1〕物性角色:
形式FOR:一种液体食物;
构成CON:由淀粉或糖质原料制成酒醅或发酵醪经蒸馏而得,用熟粮食和菌种混合培养,制成曲后,再和粮食混合同时进行糖化和发酵制成粮食酒、再蒸馏。根据香型,可以分为酱香型、浓香型、清香型、米香型等。
单位UNI:不定:点、些;名量:杯、瓶、壶、碗、口、盅,等等;类属:种;
评价EVA:中档、优质、劣质、普通、名优、假冒、新型,等等;
施成AGE:加工、生产、勾兑、酿造、兑制,等等;
功用TEL:喝、饮用、食用,等等;
处置HAN:倒、命名、购买、送、销售、掺、装、卖、进口,等等;
〔2〕句法格式:
S1:CON +_
如:清香型~|米香型~|浓香型~|酱香型~
S2:Num + UNI +_
如:一杯~|一碗~|一种~|一些~|一点~|一口~|一瓶~|一壶~|一种~|一盅~
S3:EVA +(的+)_
如:高档~|中档~|低档~|劣质~|名优~|假冒~|新型~
S4:AGE +_
如:加工~|生产~|勾兑~|酿造~|兑制~
S5:TEL +_
如:喝~|食用~|饮用~
S6:HAN +_
如:倒~|命名~|购买~|送~|卖~|销售~|进口~|掺~|装~
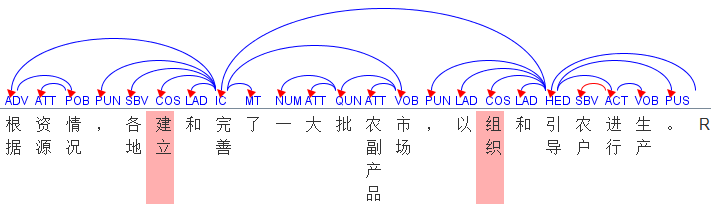
图 1 依存视图示例
2) 构建了大规模、多领域、多视图句法树库
在句法树库构建方面已取得很大进展,相关论文发表于2014年8月在爱尔兰都柏林召开的COLING-2014上和中文信息学报2015年第3期和第5期,具体内容包括:
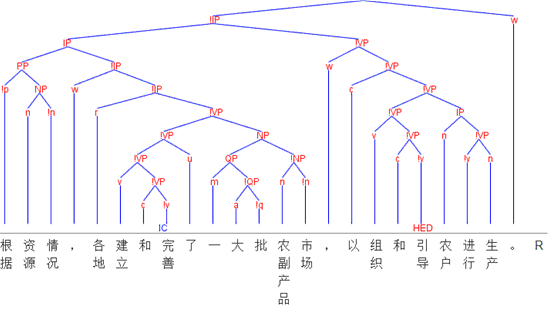
图 2 短语结构语法视图示例
(1)设计了一套依存句法标注体系及标注规范。部分依存关系类型继承自哈工大依存树库,新增的依存关系类型包括话题、强调、间接宾语、行为宾语、数量补语、共享并列等;
(2)设计了由依存视图向短语结构视图转换的算法并进行了程序实现,开发了一套支持依存和短语结构两个视图的标注工具。图 1和图 2分别是句子“根据资源情况,各地建立和完善了一大批农副产品市场,以组织和引导农户进行生产。”的依存视图和短语结构语法视图,后者根据所设计的算法自动生成。
(3)已完成560万字句法树库的标注,其中500万字为人民日报语料,60万字为微博语料(基于NLPCC2012微博情感评测语料)。其中1.4 万句新闻语料(人民日报)已可免费共享。
(4)基于这一系列树库,通过句法分析实验考察质量、规模、领域差异等因素对中文依存分析的影响,实验结果表明:(a)树库规模和质量均与句法分析精度成正相关关系,质量应先于规模因素被优先考虑;(b)通用树库和领域树库之间的差异程度与前者对后者的替代性成相关关系;(c)两种树库混合使用的效果同样与领域差异有关。
3) 设计了汉语语病分析模型
在语言文本中,语病的分析和识别是一个非常重要的基础性问题,在网络语言中,该问题尤为突出。为此,本项目开展了针对性的研究。
本项目提出了基于深度神经网络与多标记分类的病句检测方法(参图3)。
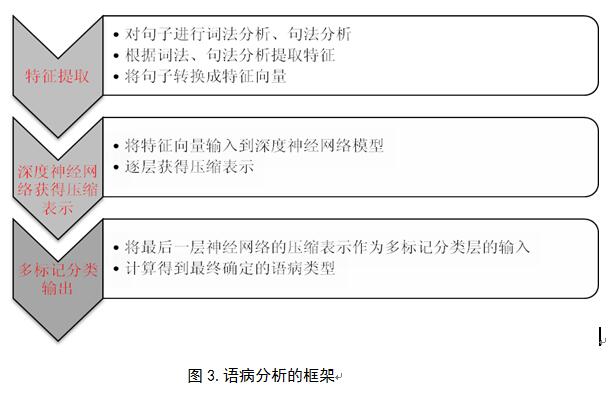
基本思想是通过从句子中提取特征,将句子变为特征向量;再将特征向量输入到深度神经网络模型中,获得深层次特征表示;最后针对于多标记分类的神经网络输出,获得最终多标记分类结果,从而准确定位句子究竟包含哪些错误。实现了将句子的特征表示升级到基于神经网络的隐藏层表示中,通过多标记的方法输出可能的语病,从而完成病句的检测。可以识别句子中的多种语病,避免了人工选择特征,同时也能确保多种语病预测的准确度。
我们提出的方法已经申请专利。
4) 提出了一种问题理解的方法
本项目还研究了一种问答系统中问句理解的方法。主要思想是基于循环神经网络方法,将问句理解中意图识别和槽填充这两个任务及其关联性进行联合学习,基于循环神经网络来联合建模一同解决意图识别和槽填充,利用这两个任务之间的关联性更好地实现两个任务。在不同的数据集上测试表明,本方法能够提高两个任务的准确率,可以用于问答系统中的问句理解。图4是基本构架图。
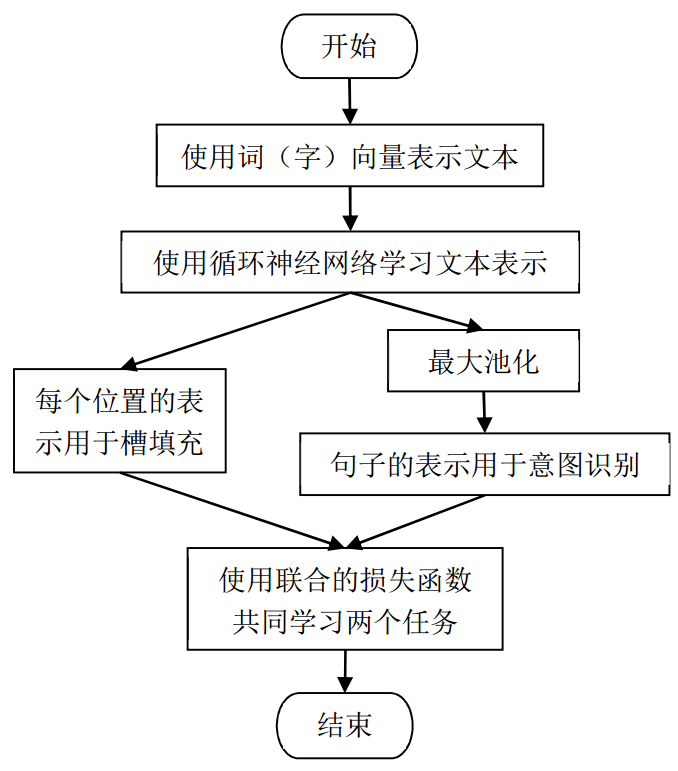
图4. 问答系统的问题理解框架
上述成果已申请发明专利。
5) 实现了名词物性角色的在线标注众包平台
名词物性角色在线标注系统主要提供了句子的自动筛选和预标功能。从生语料(LDC Chinese Gigaword)中,只抽取含目标名词和一个待标动词的句子,降低动词的搭配歧义。
在线标注系统的基本功能框架如下图5所示。
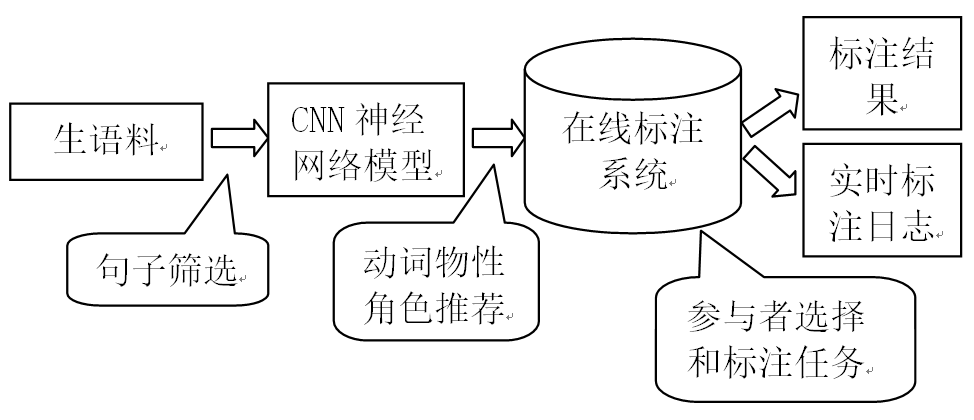
图5. 在线标注平台的实现框架
其中,句子筛选模块用于抽取含目标名词和一个待标动词的句子。CNN神经网络模型:提供了相应名词的动词物性角色推荐。
在线标注系统为参与者提供了便捷的标注界面,并保存标注结果和实时的标注日志。
上述成果已经申请软件著作权保护。
①阶段性成果清单
论文:
1)王璐璐、袁毓林《述结式与“把”字句的构式意义互动研究》,《语言教学与研究》,2016年第3期。
2)王璐璐、孙薇薇、袁毓林《“把”字句的自动释义与句式变换研究》,《计算机工程与应用》,2015年第19期。
3)周韧《兼类说反思》,《语言科学》2015年第5期。
4)宋作艳、赵青青、亢世勇《汉语复合名词语义信息标注词库:基于生成词库理论》(《中文信息学报》2015年第3期)
5)Likun Qiu, Yue Zhang, Peng Jin, Houfeng Wang, Multi-view Chinese Treebanking. Proceedings of COLING 2014, 2014-08-23
6)Likun Qiu and Yue Zhang, ZORE: A Syntax-based System for Chinese Open Relation Extraction. Proceedings of EMNLP 2014. 2014-10-25
7) Likun Qiu, Yue Zhang, Yalan Lu. Syntactic Dependencies and DistributedWord Representations for Chinese Analogy Detection and Mining. Proceedings of EMNLP 2015,2015-09-21
8)邱立坤,金澎,王厚峰,基于依存语法构建多视图汉语树库,中文信息学报,2015年第3期
9)邱立坤、史林林、王厚峰,多领域中文依存树库构建与影响统计句法分析因素之分析,中文信息学报,2015年第5期
10)吴云芳,徐艺峰,王恺然,汉语篇章级小句关系的标注体系,中文信息学报,2015年第3期
11)Wu Yunfanf, Wan Fuqiang, Xu Yifeng, Lv Xueqiang,A New Ranking Method for Chinese Discourse Tree Building,北京大学学报(自然科学版),2016年2月
12)Fei Wang, Yunfang Wu,Sentiment-Bearing New Words Mining: Exploiting Emoticons and Latent Polarities,Proceedings of CICLing 2015.
13)Yixiu Wang, Yunfang Wu, Xueqiang Lv, Multi-sentence Question Segmentation and Compression for Question Answering. NLPCC2015, LNCS9362(Springer)
14)Minghua Zhang, Yunfang Wu, ICL00 at SemEval-2016 Task 3: Translation-Based Method for CQA. Proceedings of SemEval-2016.
15) 宋洋,王厚峰,基于马尔可夫逻辑网络的中文零指代消解,计算机研究与发展,2015(09),2114-2122
16) 宋洋,王厚峰,共指消解研究方法综述,中文信息学报,2015(1),1-12
17) 陈晨,王厚峰,中文跨文本人名同名同指消解研究,江西师范大学学报:自然科学版, 2015, 02期(2),111-116
18)RuiCai, Houfeng Wang, and Junhao Zhang. Learning Entity Representation for NamedEntity Disambiguation. CCL&NLP-NABD 2015, LNAI 9427(Springer), 267-278
19)RuiCai, Miaohong Chen, and Houfeng Wang. Nonparametric Symmetric CorrespondenceTopic Models for Multilingual Text Analysis. NLPCC2015, LNCS9362(Springer), 270-281
20)Qing Zhang, Houfeng Wang. Not All Links Are Created Equal: An Adaptive Embedding Approach for Social Personalized Ranking. SIGIR-2016, July 17-21, 2016, Pisa, Italy
21)Qing Zhang, Houfeng Wang. Collaborative Filtering with Generalized Laplacian Constraint via Overlapping Decomposition, 2016, 2329-2335
专利:
1) 一种基于深度神经网络与多标记分类的病句检测方法, 申请号:201510408379.4
2)一种基于深度学习的会话情感自动分析方法,申请号:201510731781.6
3)一种问答系统中的问句理解方法,申请号:201610512191.9
软件著作权:
1)GLEANER众包平台系统V1.0, 登记号:2015SR137669
2)领域适应的汉语分词系统V1.0,登记号:2015SR161286
3)汉语名词物性知识在线加工系统V1.0,登记号:2016SR172188
课题组供稿
