![]()
![]()
一、研究进展情况(可另加附页)
主要内容:①研究计划总体执行情况及各子课题进展情况;②调查研究及学术交流情况(调研数据整理运用、文献资料收集整理、学术会议、学术交流、国际合作等);③成果宣传推介情况(成果发布会、《工作简报》报送情况、国家社科基金专刊投稿及采用情况等);④研究中存在的主要问题、改进措施,研究心得、意见建议;⑤其他需要说明的问题。
① 研究计划总体执行情况及各子课题进展情况
本项目于2012年12月28日获批立项。项目执行时间是2013年1月 — 2017年12月。本项目的计划与时间安排如下:
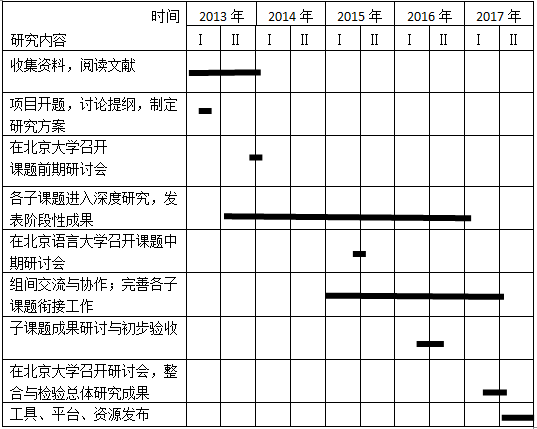
到2014年6月底,项目实施一年半,执行时间还不到项目总计划时间的三分之一。我们参照项目的上述计划进度,顺利推进项目,开展相关研究。
总体而言,在过去的一年半时间里,我们完成了相应时间内预期的任务:知识库的构建取得阶段性进展,制定了知识表示框架,填写了部分词汇的知识;在多级语料库的加工与挖掘方面,完成了规范的制定和试标工作,为后续规模化的加工打下了良好的基础;设计了众包平台的总体框架,以语篇的指代关系标注为例,在众包平台上发布标注任务;目前已通过使用平台开始指代关系的标注,并得到一定量的宝贵数据;在多视角语义分析方面也取得了一系列的成果,缩略语识别、情感分析、实体关系分析等均取得研究进展。
迄今为止,我们已经发表学术论文23篇,接受待发表的论文7篇,共计30篇,已经达到了计划的全部论文数,论文均标有本项目资助号。其中有多篇论文发表于计算语言学领域的顶级国际会议。此外,还申请专利1项。可以说,本项目圆满完成了相应时期的任务。
下面分别介绍各子课题的进展情况。
子课题1:基于生成词库理论和论元结构理论的语义知识体系研究
(1) 已经制定汉语名词的物性结构描写和标注体系,并通过试描述和组内多次讨论交流,对规范作了反复调整和完善。
(2) 以规范为依据描述了3000个左右的名词的物性结构,共计200多万字。对于高频名词的物性结构标注已经基本完成,初步构造了一个面对网络文本分析的语言知识库。
(3) 建立了一套汉语动词、形容词的论元结构描写体系和语义角色的标注体系和规范,并且在北京大学现代汉语句法树库的语料上标注了10多万字,正在配备相关的索引软件。
(4) 研制了一个在线汉语谓词语义知识库,包括为15,000多个常用动词和形容词的每一个义项(约40,000个条目)编制语义角色框架文档,内容包括:词形、拼音、词性、释义、语义角色及其定义、配位方式及其实例、真实文本中的例子等。
子课题2:网络文本的多级加工与语言知识挖掘研究
(1) 制定了汉语语料标注的系列规范,包括“多视图的汉语树库标注规范”,“汉语句际关系的标注体系”,“汉语口语语料库对话行为标注体系”等。
(2) 开发了多级多视图语料标注的系列计算机辅助软件,并通过了试标注的检验,达到了较好的效果。
(3) 为了分析网络语言的特点,标注了部分网络微博语料和口语对话语料中的依存关系和对话行为。
(4) 研究了网络文本中的信息挖掘方法和对话语料中的对话行为分析方法。为多视角的语义分析提供了依据。
子课题3:基于群体智慧的知识资源加工技术及众包平台研究
(1) 设计了众包平台的基本构建,在参与中包任务的用户使用层面,设计实现了展示模块,语料(知识)加工模块,候选答案推荐模块。
(2) 为检查用户对语料(知识)加工的质量,设计了参与用户的行为跟踪记录模块,通过日志形式,动态记录用户的行为轨迹。
(3) 利用众包平台,发布了单数指代词的指代关系标注任务。并已有3人参与指代关系标注的任务,目前通过双盲重复标注的方式已完成了2025篇文章的标注,同时也获得了相关行为的日志信息,我们已对标注情况进行初步分析,以进一步完善平台。
(4) 利用众包平台,正在设计实现句间关系标注的任务,设计工作已基本完成,很快便可发布加工任务。
子课题4:知识与统计相结合的多视角文本语义分析技术研究
(1) 研究了微博语料的分词方法。不同于规范的文本,微博的表达十分随意,新词频现,用词不囿于通常的规律。但微博的标点句短,非汉字的符号(包括标点)多,利用这一特点,实现了微博分词模块。
(2) 研究了跨语言的情感分析方法,特别是,研究了利用英语的情感词表自动获取汉语情感词的方法。这对于情感语义的分析将是非常重要的基础资源。
(3) 研究了汉语缩略语的分析和预测方法。在网络上,存在大量的缩略语现象。如何预测缩略语,建立缩略语与完整形式之间的关系,是分析理解缩略语的基础。
(4) 研究了中文的指代方法,包括文本内的指代关系和跨文本的同指关系。在文本内的指代关系分析方面,我们重点研究了汉语零型指代的消解问题,在跨文本的指代消解中,重点研究了实体链接问题。
② 调查研究及学术交流情况(调研数据整理运用、文献资料收集整理、学术会议、学术交流、国际合作等)
过去的一年半时间正好是项目的开始期,按照研究的计划安排,调查研究是本时期最重要的任务。为此,我们开展了如下工作:
(1) 进行了大量的数据收集和分析:通过自动采集方式爬取了新浪微博、口语对话、博客、网上新闻等数据,同时,也收集了一定量的语音-文字转换的结果数据。本项目收集上述数据的主要原因是,微博是典型的网上语言,而且是最具代表性的非规范语言特征。而口语对话则在一定程度上代表了聊天语言现象(包括即时通信),博客是一种相对规范的语言表示。收集语音-文字转换数据主要原因是随着移动互联网的发展,语音将成为重要的信息表示形式。语音的处理通常需要先转换为文本信息,以进一步分析语义信息,这就需要分析相关材料。
(2) 收集查阅了大量的文献资料。为了便于本项目更有效的开展,我们对国内外的研究进行了调研,重点查阅并收集了近几年来相关研究的文献资料,包括社交媒体的语言处理、不规范语言的处理方法、相关的语言知识库及语料库加工方法和加工平台的研究状况。查阅文献资料100多篇(部)。为本项目的优化实施起到了重要作用。
(3) 学术会议与学术交流方面,项目各子课题多次进行了小组讨论。参加了一系列的学术会议,包括2013年在保加利亚举行的国际顶级计算语言学会议ACL,2013年在美国举行的国际权威计算语言学会议EMNLP,2013年在日本举行的IJNLP会议,以及在新加坡、台湾等地举办的重要语言学国际学术会议和计算语言学国际学术会议。在国内,参加了多个重要会议,包括2013年全国计算语言学,词汇语义学会以,中文计算会议等,项目首席专家还应邀在2013年的第14届汉语词汇语义学会议作特邀报告,并应邀参与哈佛大学中文文本挖掘的研讨会。此外,还与台湾元智大学、香港理工大学合作开始了相关的合作研究。
③ 成果宣传推介情况
在项目实施中,我们在多个不同场合介绍我们的项目情况。2013年在郑州召开的汉语词汇语义学会以(CLSW2013)上,项目首席专家王厚峰作为会议的特邀报告人(Keynote Speaker),重点介绍了本项目的情况和研究成果,而后在洛阳外国语学院、黑龙江大学、以及应邀访问美国哈佛大学时,王厚峰均分别介绍了本项目的研究成果;在2013年6月到台湾参加会议期间,也到交通大学介绍了本项目的研究情况。此外,我们也在计算语言学有影响的国际会议、国内会议报告相关的成果,起到了很好的推介作用。
当然,在这一年半的时间里,我们主要注意到了向本领域学术期刊和学术会议投稿,今后,我们将注意向国家社科基金专刊的投稿。
④ 研究中存在的主要问题、改进措施,研究心得、意见建议
本项研究我们基本上按照计划进行,并针对研究中的问题按课题进行研讨,总的来看,我们按正常方式推进。目前暂没有特别的建议。
二、研究成果情况
①代表性成果简介
我们围绕项目任务开展了多方面的研究,取得了一系列的成果,下面仅介绍几项代表性的成果。
(1) 建立了名词的物性结构体系
根据Pustejovsky (1995、2006)的物性结构描写框架,结合汉语的实际情况,构建了一套汉语名词的物性描写体系。说明如下:
(1)形式(formal,简写为FAL):名词的分类属性、语义类型和本体层级特征。比如,“石头”是“有形物质、自然物”;
(2)构成(constitutive,简写为CON):名词所指的事物的结构属性,包括:构成状态、组成成分、在更大的范围内构成或组成哪些事物、跟其他事物的关系,也包括物体的大小(magnitude)、形状(shape)、维度(dimensionality)、颜色(color)和方位(orientation),等等。比如,“石头”的构成是“矿物;可以根据下列颜色、形状、作用等属性进行分类:彩色、黑色、红色、褐色、白色、圆形、柱形、棱角分明、保健,等等”;
(3)单位(unite,简写为UNI):名词所指事物的计量单位,也即跟名词相应的量词;
(4)评价(evaluation,简写为EVA):对名词所指事物的主观评价、情感色彩。比如,对“水”的评价有“清、清澈、清洁、脏、浑、浑浊”;
(5)施成(agentive,简写为AGE):名词所指的事物是怎样形成的,如创造、天然存在、因果关系等。比如,“椅子”的施成是“制作、做、加工、编制”等等;
(6)材料(material,简写为MAT):创造名词所指的事物所用的材料。比如,“椅子”的材料是“木头、竹子、藤子、木、竹、藤、钢、铁、塑料、硬板”等等;
(7)功用(telic,简写为TEL):名词所指的事物的用途和功能。比如,“椅子”的功用是“坐”等等;
(8)行为(action,简写为ACT):名词所指的事物的惯常性的动作、行为、活动。比如,“水”的行为是“流、流动、奔腾、翻滚、滴、淌、流淌”等等;
(9)处置(handle,简写为HAN):人或其他事物对名词所指的事物的惯常性的动作、行为、影响。比如,对“水”的处置是“打、舀、取、蓄、洒、放、排、倒、喷、泼、玩儿”等等。
目前,已经完成了3000个名词。下面仅以“商店”为例作说明:
商店 shāngdiàn〈名词,中性〉在室内出售商品的场所。
〔1〕物性角色:
形式FOR:机构、场所、人造物;
构成CON:可以根据所出售的东西类型进行分类,如:百货、五金、音乐器材、工艺品、土特产、综合,等等;也可以根据其类型、等级、地区等进行分类,如:大型、新型、高档、高级、连锁、水上、地下、社区,等等。
单位UNI:个体:个、家、座,等等;集合:批、部分、种、类、排,等等;不定:各、每个、些,等等;
评价EVA:大、小、豪华、信誉良好、鳞次栉比,等等;
施成AGE:开办、兴建、盖、建造,等等;
行为ACT:卖饮料、挂出条幅、开门、开始工作、举办、开设、开张、营业、出台促销手段
功用TEL:出售商品,等等;
处置HAN:装饰、拆除、走进、出入、洗劫、冲击、哄抢,等等
定位ORI:里、从、中、去、在、附近、到、向、通往、位于,等等。
〔2〕句法格式:
S1:CON + __
如:音乐器材~| 电脑~ | 工艺美术~ | 大型~ | 新型~ | 工艺品~ | 百货~ | 高级~ | 普通~ | 五金~| 土特产~| 食品~ | 春节用品~ | 社区~ | 服装~ | 网络~ | 化妆品~ | 零售~ | 移动电话~ | 儿童~ | NBA~ | 化学品~ | 建材~ | 烟酒~ | 专业~ | 珠宝首饰~ | 连锁~ | 批发~ | 个体~ | 计算机~
S2:Num + UNI + __
如:两个~ | 许多~ |各种~ | 一家~ | 一座~| 一些~ | 一(大)批~ | 一排~
S3:EVA +(的+)__
如:大~ | 小~ | 鳞次栉比的~ | 信誉良好~ | 豪华~
S4:AGE + __
如:开办~ | 盖~ | 建造~
S5: __ + ACT
如:~卖饮料 | ~挂出条幅 | ~开门 | ~开始工作 | ~开设 | ~开张 | ~营业 | ~开放 | ~出台促销手段 | ~举办 | ~打烊 | ~配备 | ~关闭 | ~停业
S6:__ + TEL
如:~出售商品
S7:HAN + __
如:装饰~ | 拆除~ | 进入~ | 走进~ | 出入~ | 洗劫~ | 冲击~ | 检查~ | 焚烧~ | 打砸~ | 哄抢~ | 看守~
S8:ORI + __ / __ + ORI
如:~里 | ~中 | 在~ |~内 | 到~ | 从~| ~附近 | 往~ | 去~
名词物性结构有利于信息处理中文本蕴涵推理计算,尤其对于一些名词结构中隐含谓词的还原有着重要的意义。
(2) 制定了多视图的汉语树库标注规范并实现了树库辅助标注工具
提出一套多视图的汉语树库体系,这套体系以依存视图为核心,在句法层面上仅仅标注中心语和语法角色两类信息,然后通过设计一套层次生成程序和结构功能映射规则和算法推导出层次信息和短语结构功能信息,从而自动转换出相应的短语结构树;在语义层面上,通过对部分语法标签的细化进一步标注语义角色标签,并通过虚词的格传递来保证语法依存和语义依存在中心语上的一致性。最终生成的多视图树库含有语法依存视图、短语结构视图和语义依存视图等三个视图。如下是依存视图的示例:
目前已有的句法结构的语料基本都是单一地针对一种句法体系,如短语结构或依存结构,不能满足实际应用的需求。我们构建多视图的树库,有助于实际使用者根据需求选择不同视图,或同时使用不同视图的信息。
为了进行了多视图树库构建的工作,我们开发了一套支持多视图树库标注的工具,该工具除基本标注功能外,还包含人机互动校对和与语法词典交叉验证的功能。用户可以方便地添加、删除依存弧,修改依存标签、检索特定标签等。下图是操作界面。
(3) 汉语句际关系的标注体系
提出了汉语复句层次上句际层级结构和逻辑关系的语料标注体系。结构关联方面主要借鉴了英语RST理论,语义关联方面主要借鉴了英语的PDTB篇章树库。小句之间通过各种语义关系的连接而形成一棵完整的层级结构树。提出了汉语句际的逻辑关系类型,这是汉语篇章分析的基础。体系如下表所示:
第1层:CLASS
第2层:TYPE
第3层:SUBTYPE
联合关系
(multi-nuclear)
并列(conjunction)
[CONJ]
○1等立(coordinate) [COOR]
○2时序(temporal) [TEMP]
○3选择(alternative) [ALT]
○4递进(progression) [PROG]
○5顺承(succession) [SUCC]
主从关系
(single-nuclear)
对比(comparison)
[COMP]
○6转折(contrast) [CONT]
○7让步(concession) [CONC]
推论(inference)
[INF]
○8因果(cause) [CAUS]
○9结果(result) [RESU]
○10目的(purpose) [PURP]
条件(condition)
[CON]
○11假设(hypothetical) [HYP]
○12条件(condition) [COND]
总分(specification)
[SPE]
○13解证(explanation) [EXPL]
○14分述(list) [LIST]
分总(summary)
[SUM]
○15总括(generalization) [GENE]
(4) 口语对话语料中对话行为的标注规范
对话行为(dialog act)指在对话中(dialog)言谈者的行为意图。自动分析对话行为可以帮助识别言谈者的意图、帮助构建对话模型、提升口语机器翻译系统的性能等。本项目第一次构建了汉语领域完整的对话行为标签集。首先,对一个语句进行言语切分(utterance segmentation),明确标示出言语的界限;然后,每个言语片段标示出一个明确的、惟一的对话行为标签。
Tag (Abbr.)
Description
Example
Statement
(S)
State a belief or an event
陈述一个信念或一个事件
我接下来图片看一下啊先
Request
(R)
Express a speaker’s desire that the hearer do something
期望听者做出一个动作或某种响应
就是这个图片 请接收一下
Open-question
(Q)
A question that can not be answered with only “yes” or “no”
不能单纯用“是”和“否”来回答的问句
产生费用怎么算?
Yes-No-question
(QYN)
A closed question which can be answered by either a “yes” or “no”
是非问句
这些图片,你是从gettyimages上面找的么?
Opinion
(O)
(B)
Express opinions or unsatisfactory towards something or some services
对事情或服务发表评价或发出抱怨
那么贵?
Yes-answer
(AY)
A positive answer to a Yes-no-question
是非问句的肯定回答
对的
No-answer
(AN)
A negative answer to a Yes-no-question
是非问句的否定回答
不是
Answer
(AQ)
An answer to an open-question
开放问句的回答
咱们的图片按照授权方式不同,分了2种
Response-ack
(RA)
Confirm that the previous request was received/accepted
对上一句需求性言语作出响应
好的
Statement-ack
(SA)
Confirm that the previous statement was received/accepted
对上一句陈述作出响应
client:抬头 北京鼎尚利合餐饮管理有限公司
server:好的!收到!
Explain-why
(EW)
Explain further the reason of the previous utterance
对上一句言语进一步解释原因
client:手机和直邮能改吗?
server:这个修改不了
server:用途由内部系统生成
Conversational opening
(CO)
Greetings and other ways of starting a conversation
开始一个对话
你好
Conversational closing
(CC)
Various ways of ending a conversation
结束一个对话
Bye Bye
Conversational continuer
(CT)
Various ways of continuing a conversation
延续一个对话
呵呵
Thanks
(TH)
Express appreciation and thanks
表示感谢等礼貌用语
麻烦了,谢谢
Downplayer
(D)
A backwards-linking label often used after THANKS to down play the contribution
对感谢用语作出礼貌性的回应
不客气
Confirmation
(CF)
Verify or confirm a previous information
对上一句言语信息进一步确认
Server:大概从1000-3000不等。
Server:图片价格大概1000-3000/张不等。
Entity
(EN)
Using non-verbal entity to convey information
用不成句的实体词语传输信息
菲尔•米克尔森
Cut
(Cut)
The first part that constitutes a complete utterance
被切断的一个言语的前半部分
server:咱们那张图呀<CUT>
server:定下来了不哈?<QYN>
Chat
(CHAT)
Chat unrelated to business
完全与业务无关的闲聊
Uncertainty
(U)
Uncertain information
不确定的信息
(5) 设计实现了众包平台,并发布了单数人称代词的标注任务
为了便于知识资源的加工,我们开发了一个众包平台,界面如下所示:
基本框架如下:
基于众包平台发布了单数人称代词的指代关系标注。见如下界面:
通过众包模式(Crowdsourcing)建设大规模的语料库,可以让大量的非专业人员参与语料库标注的工作,这有助于降低加工成本,提高加工效率。
(5) 设计实现了面向网络短文本的汉语切词模块
网络语言超出了通常规范语言的很多限制,使得计算机处理变得十分困难。而计算机分析中文的第一步通常是切词。一般切词工具在新闻文本上可以达到95%的F 值,在微博上则只有大约82% 。为此,我们特别研究了面向网络短文本的汉语切词方法,特别是针对微博的切词方法。
现有的切词方法大都使用有指导的序列标注模型,如CRF。基本思想是对每个汉字赋予一个标记,如,某个字是一个词的开始字(标B)或者不是一个词的开始字(标N)。已有的研究表明,有指导方法得到的切词效果有着明显的优势。但是,有指导的方法需要大量的有标训练数据,而构建有标训练数据既费时又费力。如何充分利用现有数据的特点便成为一个重要的问题。通过观察,我们发现,与一般的新闻文本相比,微博数据有明显的自然标记信息。下表是我们对一般新闻和微博中各类符号分布统计的比较值:
文本类型
汉字
英文字
数字
标点符号
一般新闻
85.7%
0.6%
0.7%
13%
微博
66.3%
11.8%
2.6%
19.3%
显然,微博中的非汉字比例大幅上升,比一般新闻的非汉字比例增加一倍以上。对于汉语分词而言,英文字母,数字以及标点符号都是自然的断词符号:自然标记符后面的汉字是词的开始字(B),同样,自然标记前面的一个汉字则是词的末尾字。可以充分利用这些自然标注改进网络短文本的切词处理。我们基于上述观察,自动获得了大量的特殊标注信息,并利用这些信息设计了切词模块,实验表明,我们所提方法与已有的方法相比,F值有显著提升,达到了 87.5%。
注:2010年立项的重大项目主要填写2012年6月以来的研究成果情况。
|
序号 |
成果名称 |
作者 |
成果形式 |
刊物名或出版社、刊发或出版时间 |
字数 |
转载、引用、获奖等情况 |
|
1 |
采用无标注语料的动词和形容词主观性评级 |
徐戈,蒙新泛,王厚峰 |
论文 |
软件学报,2013(5) |
1.5万字 |
|
|
2 |
The Acquisition of Chinese Ergative Verbs and the Verification of Relevant Rules in Semantic Role Labeling |
汪梦翔等 |
英文 论文 |
CLSW 2013, LNAI 8229, Springer-Verlag Berlin Heidelberg |
|
|
|
3 |
Improving ChineseWord Segmentation on Micro-blog Using Rich Punctuations |
张龙凯等 |
英文论文 |
Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, August 2013 |
|
|
|
4 |
Learning Entity Representation for Entity Disambiguation |
何正焱等 |
英文论文 |
Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, August 2013 |
|
|
|
5 |
“对不起”话语标签的形成及功能 |
汪梦翔等 |
论文 |
湖北社会科学,2013(8) |
7500 |
|
|
6 |
Judgment, Extraction and Selective Restriction of Chinese Eventive Verb |
汪梦翔等 |
英文 论文 |
Proceedings of 2013 International Conference on Asia Language Processing (IALP 2013) IEEE Computer Society |
|
|
|
7 |
Exploiting Hierarchical Discourse Structure for Review Sentiment Analysis |
Fei Wang, Yunfang Wu |
英文论文 |
Proceedings of 2013 International Conference on Asia Language Processing (IALP 2013) |
|
|
|
8 |
基于多步聚类的汉语命名实体识别和歧义消解 |
李广一,王厚峰 |
论文 |
中文信息学报,2013(5) |
1万字 |
|
|
9 |
Generalized Abbreviation Prediction with Negative Full Forms and Its Application on Improving Chinese Web Search |
Xu Sun, Wenjie Li, Fanqi Meng, Houfeng Wang |
英文论文 |
International Joint Conference on Natural Language Processing, Oct. 2013 |
|
|
|
10 |
Exploring Representations from Unlabeled Data with Co-training for Chinese Word Segmentation |
张龙凯等 |
英文论文 |
Proceedings of the EMNLP2013,Oct.2013 |
|
|
|
11 |
Efficient Collective Entity Linking with Stacking |
何正焱等 |
英文论文 |
Proceedings of the EMNLP2013,Oct.2013 |
|
|
|
12 |
Chinese Discourse Relation Recognition Using Parallel Corpus |
Yifeng Xu, Yunfang Wu |
英文论文 |
9th International Conference on Computational Intelligence and Security |
|
|
|
13 |
基于生成词库论和论元结构理论的语义知识体系研究 |
袁毓林
|
论文 |
中文信息学报,2013(6) |
1.2万 |
|
|
14 |
基于中文维基百科的词语语义相关度计算 |
万富强,吴云芳 |
论文 |
中文信息学报,2013(6) |
1.0万 |
|
|
15 |
社交网络中的社团结构挖掘 |
范超,王厚峰 |
论文 |
中文信息学报,2014(1) |
1.2万 |
|
|
16 |
汉语词类划分应重视“排他法” |
周韧 |
论文 |
汉语学习,2014(1) |
1.4万 |
|
|
17 |
也谈与“的”字结构有关的谓词隐含 |
宋作艳 |
论文 |
汉语学习,2014(1) |
1.2万 |
|
|
18 |
基于句式结构的汉语图解析句法设计 |
彭炜明等 |
论文 |
计算机工程与应用,2014(3) |
1.2万字 |
|
|
19 |
现代汉语“对象格”自动识别研究 |
汪梦翔等 |
论文 |
计算机工程与应用,2014(8) |
1.2万字 |
|
|
20 |
中文信息处理的词法问题 |
彭炜明等 |
论文 |
中文信息学报,2014(2) |
1.2万字 |
|
|
21 |
股市市场情感词表的自动挖掘与构建 |
王菲, 吴云芳 |
论文 |
2014汉语词汇语义学研讨会议(CLSW2014) |
1.0万字 |
|
|
22 |
基于序列模式的应答需求句识别 |
徐艺峰, 吴云芳 |
论文 |
2014汉语词汇语义学研讨会议(CLSW2014) |
|
|
|
23 |
The Processing of Dummy Verbs in Semantic Role Labeling |
汪梦翔等 |
英文 论文 |
CLSW 2014 将在LNAI Springer-Verlag Berlin Heidelberg出版 |
|
|
|
24 |
基于依存语法构建多视图汉语树库 |
邱立坤、金澎、王厚峰 |
论文 |
中文信息学报 |
10000 |
(已录用) |
|
25 |
Collaborative Topic Regression with Multiple Graphs Factorization for Recommendation in Social Media |
Qing Zhang, Houfeng Wang |
英文论文 |
Proceedings of the 25th International Conference on Computational Linguistics |
|
(已录用) |
|
26 |
Building a Multi-view Chinese Treebank |
Likun Qiu, Yue Zhang, Peng Jin and Houfeng Wang |
英文论文 |
Proceedings of the 25th International Conference on Computational Linguistics |
|
(已录用) |
|
27 |
“把”字句的自动释义与句式变换研究 |
王璐璐 孙薇薇 袁毓林 |
论文 |
计算机工程与应用 |
1.3万字 |
(已录用) |
|
28 |
基于规则的汉语名名组合的自动释义研究 |
魏雪、袁毓林 |
论文 |
中文信息学报 |
1.3万字 |
(已录用),拟在2014(3)发表 |
|
29 |
共指消解研究方法综述 |
宋洋,王厚峰 |
论文 |
中文信息学报 |
1.5万字 |
(已录用) |
|
30 |
Feature-Frequency-Adaptive Online Trainingfor Fast and Accurate Natural Language Processing |
Xu Sun, Wenjie Li, Houfeng Wang, Qin Lu |
英文论文 |
Computational Linguistics |
|
(已录用,在线版已发:http://www. mitpressjournals. org/doi/pdf/10.1162/ COLI_a_00193) |
|
31 |
一种基于文档词汇特征变化的突发事件检测方法 |
王厚峰, 张龙凯 |
专利 |
中华人民共和国知识产权局 |
|
(已申报) |
课题组供稿
